O algoritmo do k-vizinho mais próximo
Tabela de Conteúdos:
Dica: Após visitar um link da tabela de conteúdos, utilize a tecla de retorno do seu navegador para voltar para a tabela.
Sobre o algoritmo do k-vizinho mais próximo
O algoritmo do k-vizinho mais próximo, chamado também de knn (k-nearest neighbourg, em inglês) é uma variação do vizinho mais pŕoximo.
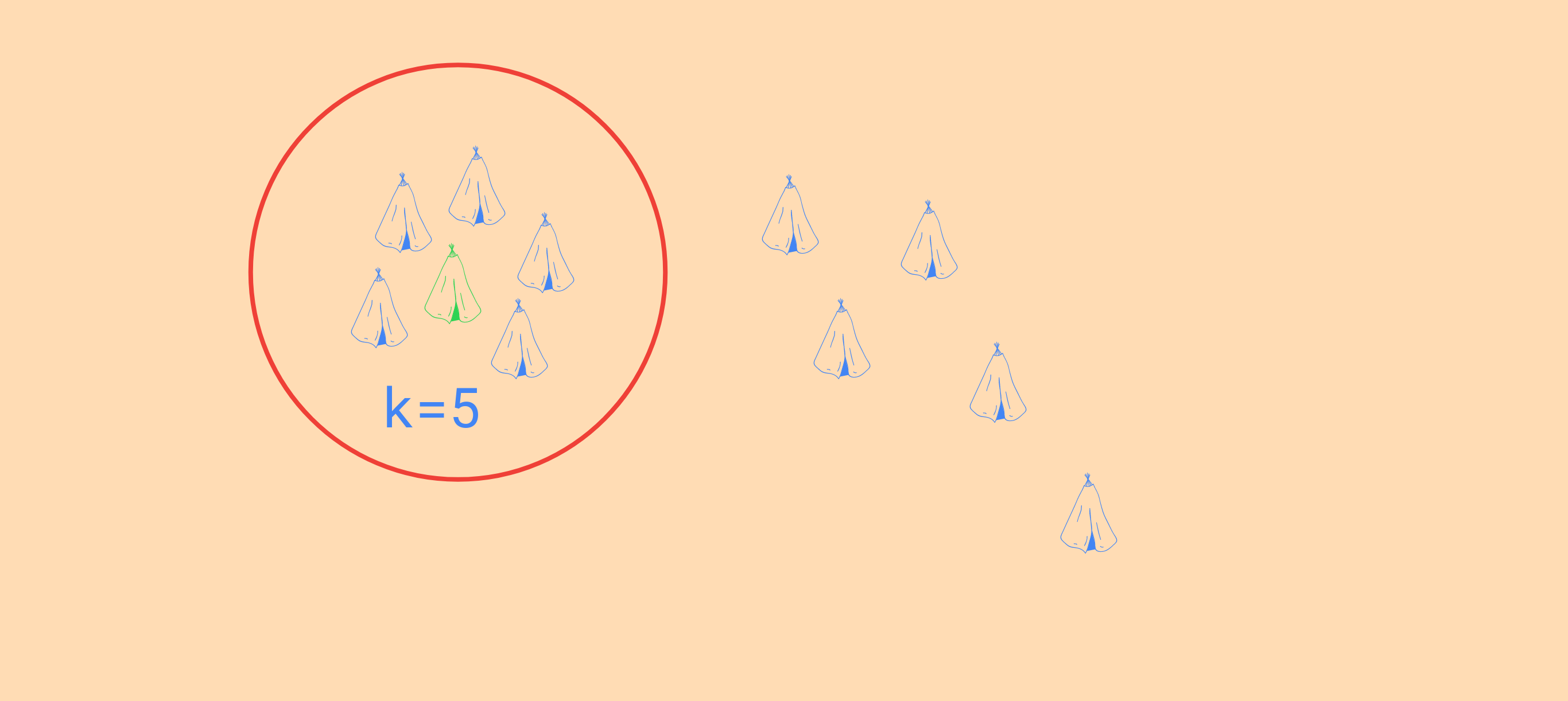
A idéia é, ao invés de classificar uma imagem de teste como do tipo daquela do conjunto de treino para a qual tiver a menor distância, seleciona-se
primeiro as ( um número inteiro) imagens do conjunto de treino com as menores distâncias para a imagem de teste a ser classificada.
Em seguida, classifica-se a imagem de teste por consenso, ou seja, seleciona-se entre as imagens aquela cuja classe ocorreu maior numero de vezes.
Vamos ver um exemplo:
Vamos utilizar para o exemplo.
Suponha-se que ao verificar as distâncias da imagem de teste a ser classificada para as imagens no conjunto de treino, as menores distâncias
com as respectivas classes foram:
- gato
- cachorro
- navio
- carro
- cachorro
Observe que, apesar da classe com a menor distância ser gato, a classe cachorro ocorreu mais vezes, portanto, será a classe utilizada.
A ideia é diminuir a possibilidade de uma classe ser escolhida por uma circunstancial característica de pixeis em uma pequena região, que induza um
resultado errado. Escolher a classe que ocorreu mais vezes entre as com menor distânca é uma forma de homogenizar o resultado.
A escolha de k passa então a ser fundamental. Pode ser feita de forma aleatória, arbitrando um valor. Se muito baixo, seu efeito é pequeno, se muito
alto, o custo em esfôrço computacional aumenta.
Pode-se porém utilizar um método um pouco mais elaborado para determinar k: Separa-se uma parte dos dados de treino, por exemplo, 20% das imagens,
e testa-se com vários valores de k, observando o melhor acerto em algumas imagens de teste, e seleciona-se o k que porporcionou o melhor resultado.
Naturalmente, as imagens de treino utlizadas nesta seleção não devem ser utilizadas na classificação final, para evitar overfitting (quando o
resultado fica viciado por ser obtido com dados especializados).
Hora de estudar código Java e testar
Visite a área de código do projeto, estude a classe KnearestNeighbourgh.java.